WORLD is a C-based open source speech synthesis system. Speech synthesis mainly includes two methods: waveform splicing and parameter synthesis. WORLD is a parameter synthesis method based on vocoder. Compared with STRAIGHT, it has the advantage of reducing computational complexity. And can be applied to real-time speech synthesis. Since STRAIGHT is not an open source system, and WORLD has compared WORLD compared to STRAIGHT, both in terms of synthesized audio quality and synthesis speed, I am not going to introduce STRAIGHT here. Let’s talk about it today. The principle and use of the WORLD speech synthesis system.
The WORLD system is shown in the figure below. It consists of three modules, namely DIO, CheapTrick, and PLATINUM. The role of DIO is to estimate the Fundamental Frequency (F0) of a waveform. The CheapTrick algorithm calculates the spectral envelope based on the waveform and F0. The PLATINUM algorithm calculates the aperiodic parameter based on the waveform, F0 and spectral envelope. Let's look at the calculation principle of these parameters separately.
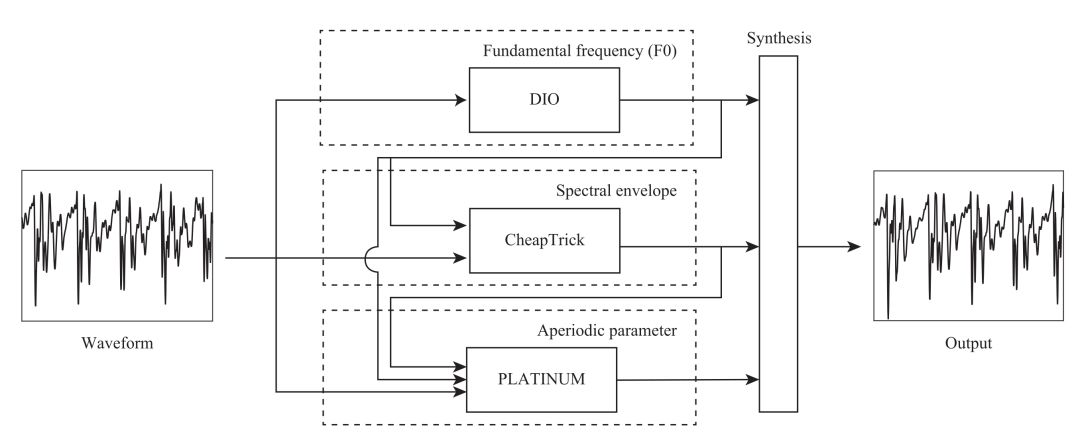
1. Calculation of F0
F0 is defined in Wikipedia: when the sounding body emits sound due to vibration, the sound can generally be decomposed into many simple sine waves. All natural sounds are basically composed of many sine waves with different frequencies, the lowest frequency. The sine wave is the pitch, while the other sine waves with higher frequencies are overtones, that is, the lowest frequency among these different sine waves is called the fundamental frequency. F0 is a very common feature that can represent sound. In WORLD, the calculation of F0 is based on DIO algorithm. The DIO algorithm mainly includes the following three steps:
The first step: use a low-pass filter with a different cutoff frequency. If the filtered signal only contains the fundamental frequency, then it is a sine wave. Since we don't know about F0 beforehand, we need multiple trials, so in this step There are many filters with different cutoff frequencies in use;
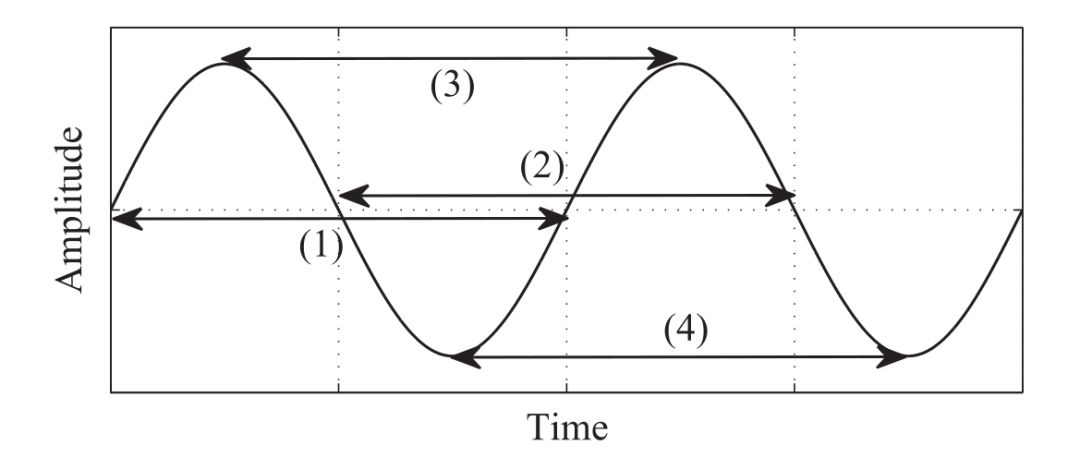
Step 2: Calculate the candidate fundamental frequency and confidence in each filtered signal. Since the signal containing only the fundamental frequency should be a sine wave, as shown in the following figure, the spans of the four intervals should be basically equal. The average of the four spans can be calculated, and the reciprocal of this value is used to represent the candidate fundamental frequency. At the same time, the standard deviation of these four spans is calculated as an indicator to measure the reliability of the fundamental frequency. The larger the standard deviation is, the larger the difference in span length is, and the reliability of taking this frequency as the fundamental frequency is lower.
Step 3: Select the candidate base frequency with the highest reliability as the final base frequency.
2. CheapTrick algorithm for estimating the spectral envelope
First, we need to understand what is the spectral envelope of speech. Voice is a timing signal. For example, for an audio file with a sampling frequency of 16 kHz, it means that in this audio, there are 16,000 sampling points per second. The computer stores it in some form of data (for example, a 16-bit integer is common). When we use a rectangular window function to process an audio, it is divided into multiple frames, so we get multiple subsequences, and then Each subsequence performs a Fourier transform operation, and a frequency-amplitude map is obtained. These graphs are displayed in the time dimension, and the spectrogram of the speech file is obtained. An actual spectrogram is shown below.
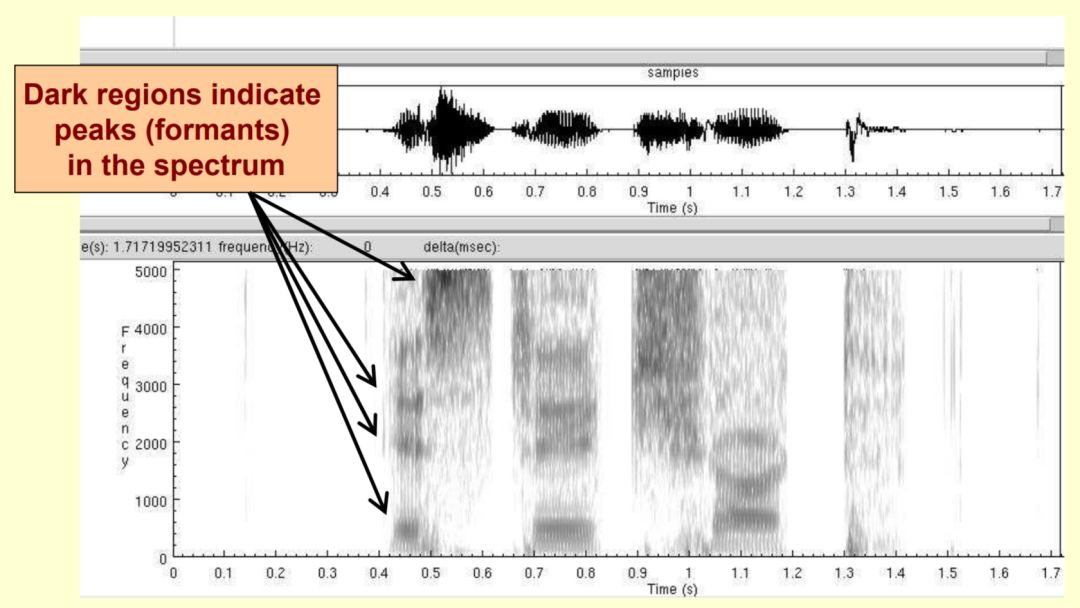
The spectral envelope is actually in a frequency-amplitude diagram, each frequency formant is connected by a smooth curve, and this smooth curve is the spectral envelope of the speech. The figure below shows the spectrum envelope in the spectrum. s position.
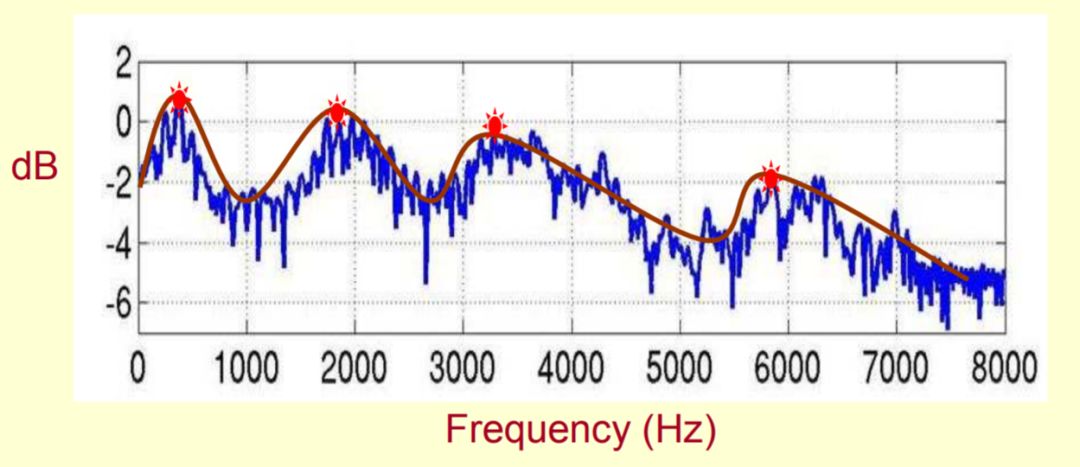
There are many algorithms for determining this spectral envelope. For example, Cepstrum is common. (Cepstrum, interestingly, the two words cepstrum and spectrum are just the first four letters to flip the position, which actually implies that their physical meanings are Some coincidence correlation...) In WORLD, the CheapTrick algorithm is used to estimate the spectral envelope. The algorithm works as follows:
First, add a Hanning window to the signal, and then calculate the power of the signal after windowed, as shown in the following (1);
Second, the power spectrum is smoothed using a rectangular window function, as shown in the following equation (2);
Finally, calculate the cepstrum of the power spectrum and do the cepstrum boost, as shown in (3)(4)(5)(6);
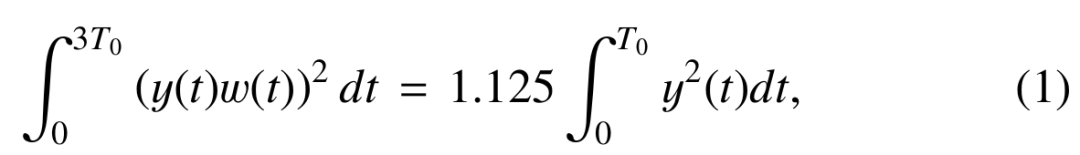
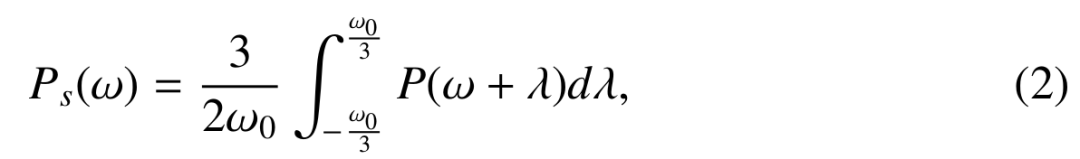
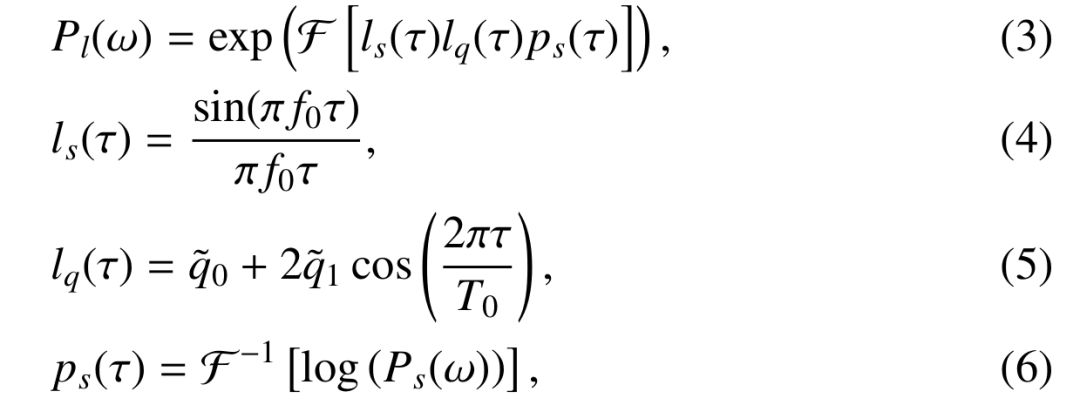
The resulting Pl(w) is the spectrum envelope we need.
3. Aperiodic parameter extraction algorithm
Aperiodic is a parameter related to mixed excitation. In order to obtain a natural sound, the excitation source cannot use only periodic signals, but also some non-periodic signals. In WORLD, aperiodic parameters can be calculated directly based on waveform, F0, and spectral envelope. This algorithm is called PLATINUM and its workflow is as follows:
First, add a window function with a width of 2T0 to the waveform, and calculate its spectrum X(w); divide X(w) by the minimum phase spectrum Sm(w) to get Xp(w), as shown in (11); Perform an inverse iFFT on Xp(w) to obtain an excitation signal, as shown in (10);
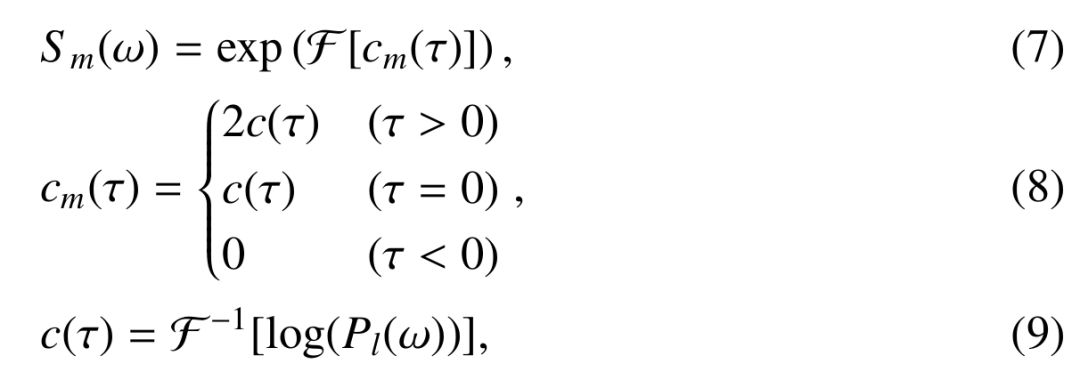

The final speech synthesis is obtained by convolving the minimum phase spectrum with the excitation signal.
Finally, take a look at how to call WORLD to synthesize a speech and the effect of the composition. The WORLD source code is based on the C language, but WORLD also has a Python wrapper library - PyWorld. For the sake of code simplicity, here we use PyWorld to demonstrate.
The PyWorld library can be installed by running pip install pyworld and pip install soundfile on the terminal. The library provides a demo code that can be used to demonstrate speech synthesis. The following piece of code uses the WORLD library to extract audio features, and based on the vocoder to synthesize new audio, the original audio and new audio waveforms are compared as shown below.
#Get the sampling point value of the audio and the sampling rate x, fs = sf.read('utterance/vaiueo2d.wav')# Use the DIO algorithm to calculate the fundamental frequency of the audio F0_f0, t = pw.dio(x, fs, f0_floor=50.0 , f0_ceil=600.0, channels_in_octave=2, frame_period=args.frame_period, speed=args.speed)# Calculate the spectral envelope of the audio using the CheapTrick algorithm _sp = pw.cheaptrick(x, _f0, t, fs)#calculate aperiodic parameters _ap = pw.d4c(x, _f0, t, fs)# Synthesize audio based on the above parameters _y = pw.synthesize(_f0, _sp, _ap, fs, args.frame_period)#Write audio file sf.write(' Test/y_without_f0_refinement.wav', _y, fs)
The figure below compares the waveform of the original waveform with the synthesized audio. The upper image is the original waveform, and the lower image is the synthesized audio waveform. It can be seen that it is basically consistent. Since the public article can only upload a piece of audio, I can only upload the synthesized audio here.
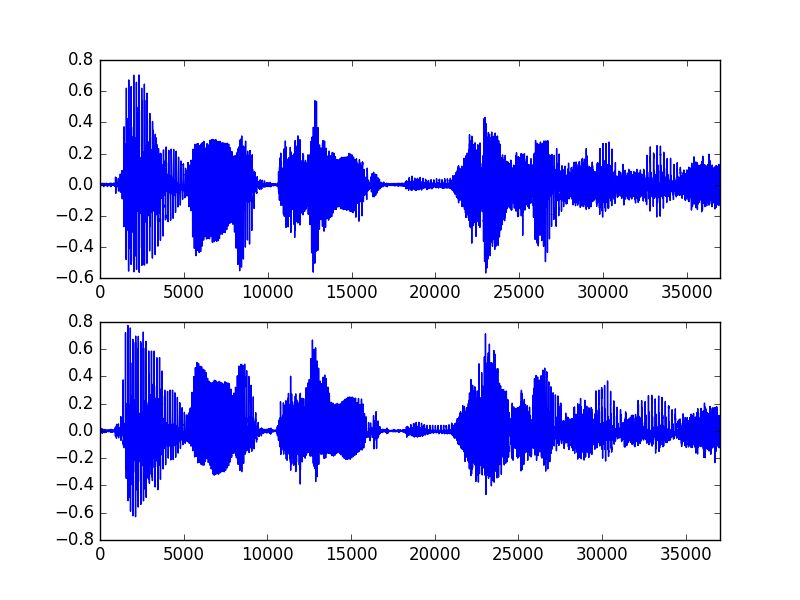
The WORLD speech synthesis system can synthesize a speech according to three parameters: F0, spectral envelope and aperiodic. Therefore, in the front-end speech synthesis research, the three features corresponding to a piece of text can be learned through deep learning technology, and then WORLD is used. Synthesized into speech.
The electrolyte material inside the electrolytic capacitor, which has charge storage, is divided into positive and negative polarity, similar to the battery, and cannot be connected backwards.A metal substrate having an oxide film attached to a positive electrode and a negative electrode connected to an electrolyte (solid and non-solid) through a metal plate.
Nonpolar (dual polarity) electrolytic capacitor adopts double oxide film structure, similar to the two polar electrolytic capacitor after two connected to the cathode, the two electrodes of two metal plates respectively (both with oxide film), two groups of oxide film as the electrolyte in the middle.Polar electrolytic capacitors usually play the role of power filter, decoupling (like u), signal coupling, time constant setting and dc isolation in power circuit, medium frequency and low frequency circuit.Non-polar electrolytic capacitors are usually used in audio frequency divider circuit, television S correction circuit and starting circuit of single-phase motor.
Electrolytic Capacitor,Aluminum Electrolytic Capacitor,High Voltage Electrolytic Capacitor,12V Electronic Components Capacitor
YANGZHOU POSITIONING TECH CO., LTD. , https://www.pst-thyristor.com