This article is a joint compilation: Blake, Gao Fei
Lei Fengnet (search "Lei Feng Net" public concern) Note: Prof. Yoshua Bengio is one of the machine learning gods, especially in the field of deep learning, he is also the author of "Learning Deep Architectures for AI" in the artificial intelligence field. . Yoshua Bengio, along with Professor Geoff Hinton and Professor Yann LeCun, created the deep learning revival that began in 2006. His research work focuses on advanced machine learning and is dedicated to solving artificial intelligence problems. He is currently one of the few remaining deep-learning professors (Montreal University) who is still fully committed to academia. This is the second of his content in his classic forward-looking speech in 2009, “In-depth Architecture of Artificial Intelligence Learningâ€. section.

The title map comes from cpacanada.ca
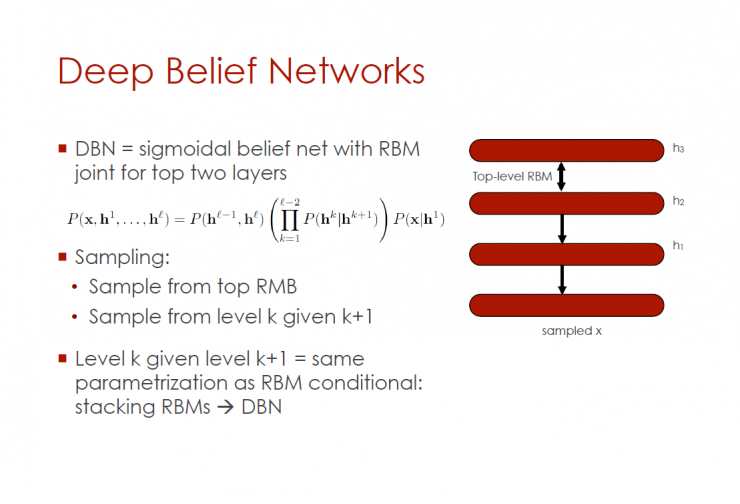
Deep Confidence Network (DBN)
DBN = inflection network at the top two layers with RBM connectors
sampling:
1. Take a sample from the top of RMB
2. When there is k+1 layer, sample from k layer
When there is k+1 layer, k layer = RBM condition, the same parameters: Stacked RBMs - DBN

Conversion from DBM (Restricted Boltzmann Machine) to DBN (Confidence Network)
RMB is determined by P(v|h) and P(h|v) P(v,h)
Indirectly defines P(v) and P(h)
Keep P(v|h) away from RBM layer and replace P(h) with the distribution value generated by RBM second layer

Deep Confidence Network (DBN)
Simple approximate reasoning
1. Get P(h|h) approximately from interconnected RBMs
2. Approximate values ​​due to different P(h) in RBM and DBN
training:
1. Variable boundaries confirm the greedy layer-by-layer training of RBMs
2. How to train all layers at the same time?

Deep Boltzmann Machine (Salakhutdinov et al, AISTATS 2009, Lee et al, ICML 2009)
Positive phase: variable approximation (average domain)
Reverse phase: continuous chain
Begin to initialize from stackable RBMs layer
Reduce the error from 1.2% to .95% to improve MNIST performance

Estimating Log Likelihood
RBMs: Requirements for Estimating Distribution Function Values
1. Refactor error values ​​to provide a cheap proxy server.
2. When the logarithmic Z is less than 25 dichotomous input values, the log Z is either analyzable or hidden.
3. Minimum threshold of annealing importance sampling (AIS)
Confidence network:
Extension of AIS (Salakhutdinov & Murray, ICML 2008, NIPS 2008)
Open questions: Finding effective ways to monitor this process

Deep convolutional structure
The structure is derived from Le Cun's team (NYU) and Ng (Stanford University): Best MNIST data, Caltech-101 objects, Face images
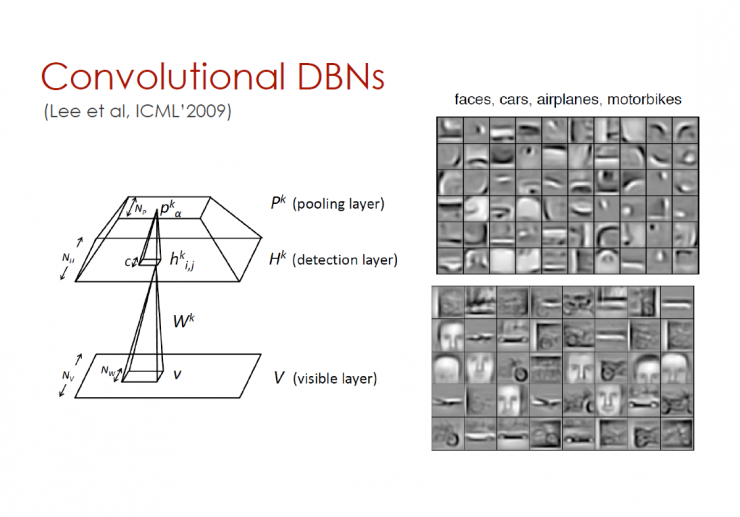
Convolutional DBNs
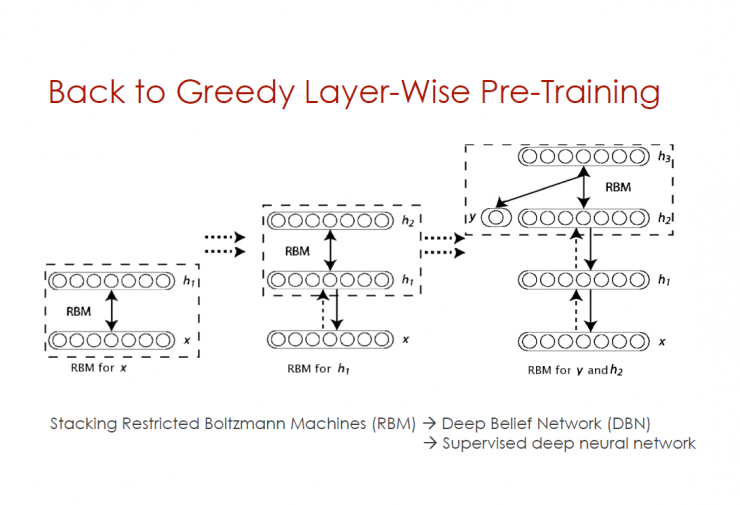
Return to Greedy Pre-training
Stacked Restricted Boltzmann Machine (RBM) - Deep Trust Network (DBN) - Supervised Deep Neural Network

Why can the classifiers obtained by DBNs (Confidence Networks) operate so effectively?
Universal principle
Are these principles useful for other single-level algorithms?
What is its working principle?
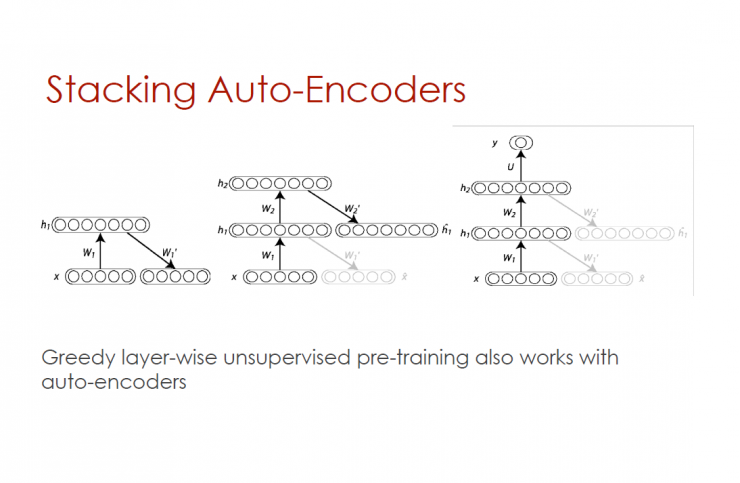
Stacked automatic encoder
Greedy layer-by-layer unsupervised pretraining also applies to automatic encoders

Automatic encoder and contrast divergence (CD)
The RBM log-likelihood gradient can be written as a convergence extension: CD-K is equal to 2 K terms and the reconstruction error value is approximately equal to 1 term

Greedy supervised training
Compared with unsupervised pre-training, greedy layer-by-layer supervised training is worse, but the training effect is better than that of a deep neural network.

Supervised fine-tuning is important
Greed layer-by-layer unsupervised pre-training phase for RBMs or MNIST automatic encoders
There are supervised renewal or supervised renewal supervised phasing, supervised phasing with hidden or fine tuning.
The ability to train all RBMs (restricted Boltzmann machines) simultaneously can achieve the same result.

Sparse automatic encoder (Ranzato et al, 2007; Ranzato et al 2008)
Sparse penalties for intermediate code
Same as sparse encoding, but has an efficient time to run the encoder.
The sparseness penalty pushes up free energy distributed in all locations.
Good results in object classification (convolutional network)
1.MNIST error is .5% breakthrough record
2. Caltech-101 up to 65% correct rate (Jarrett et al, ICCV 2009)
Get similar results in the same convolutional DBN (Lee et al, ICML'2009)
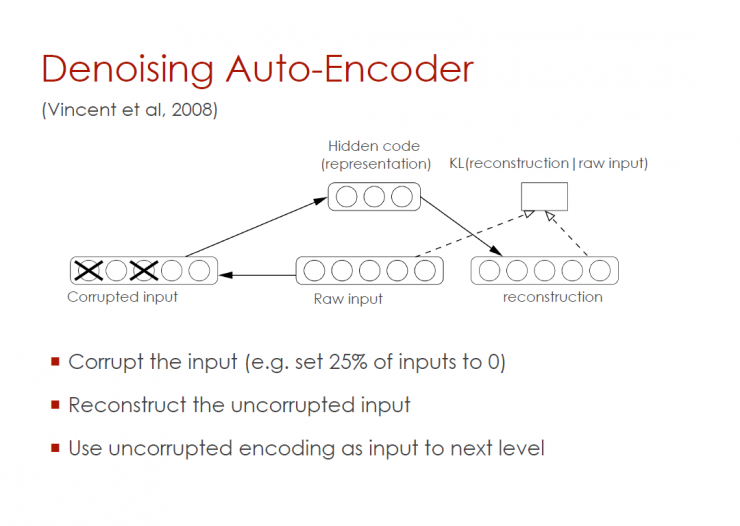
Noise Reduction Automatic Encoder (Vincent et al, 2008)
Interference input information (for example, 25% of input information is set to zero)
Reorganize disturbed input information
Use the undisturbed code as input, enter the next level
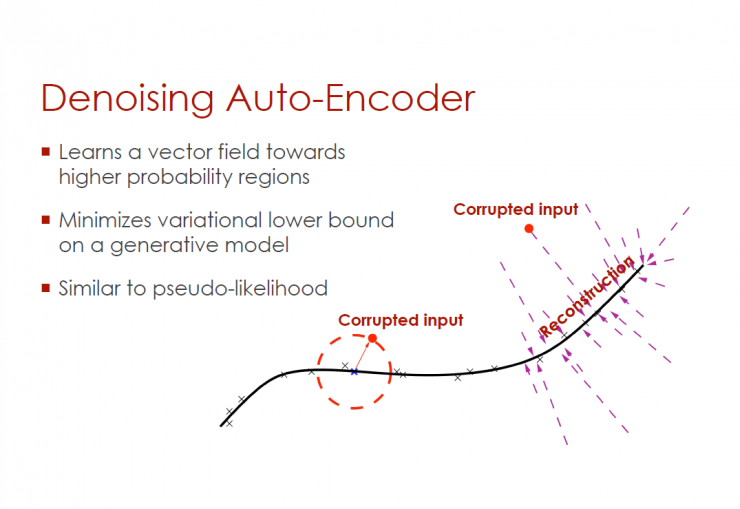
Learn the vector domain that develops towards higher probability regions
Minimizing the Variable Lower Limit of the Realization Model
Similar to pseudo-likelihood
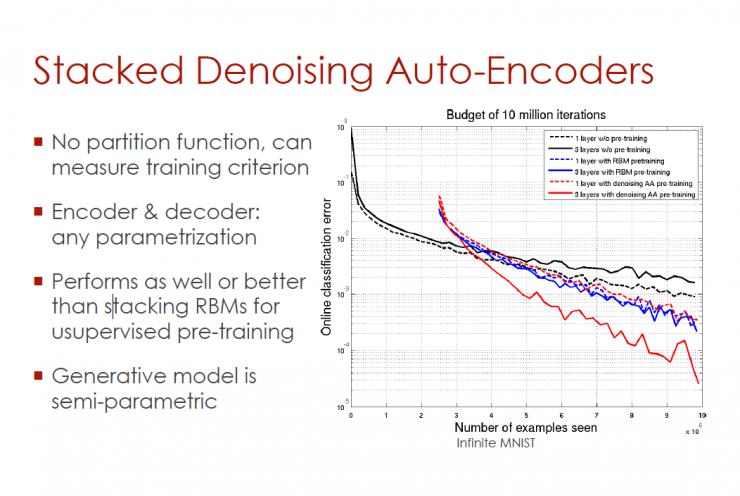
Stack type noise reduction automatic encoder
No allocation function to measure training standards
Coding and decoding: Arbitrary parameterization
Unsupervised pre-training can also be performed with stacked RBMs, or due to RBMs
Generating model is semi-parametric

Noise Reduction Automatic Encoder: Standard
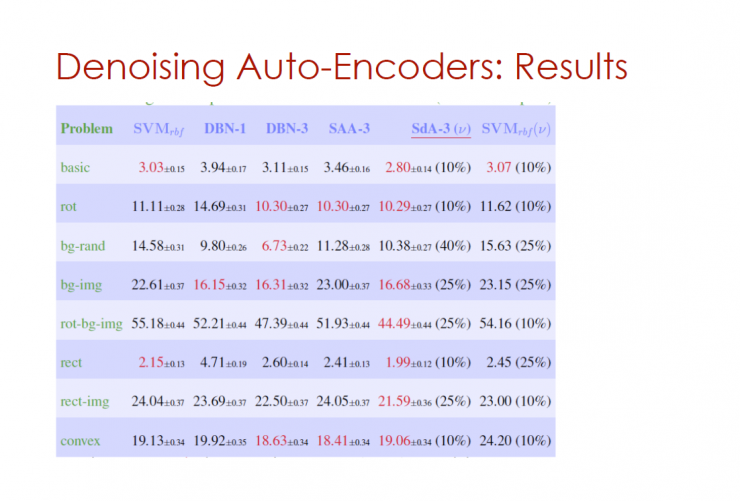
Noise Reduction Automatic Encoder: Results

Why is the effect of unsupervised pre-training so good?
Regularization hypothesis:
Unsupervised components make the model close to P(x)
The characterization of P(x) also applies to P(y|x)
Optimization hypothesis:
Unsupervised initial value close to the local minimum of P(y|x)
The local minimum minimum can be reached, otherwise the random initial value cannot reach the local minimum

Learn trajectories in function space
Within the function space, each point represents a model.
Color equivalent to epoch
Top: Trajectory w/o pre-training
Each trajectory converges at a different local minimum
There is no overlap between regions during W/o pre-training

Unsupervised Learning Regularization Matrix
Extra regularization (reduce hidden units) will damage more pre-training models
Pre-training model has less variance wrt training samples
The regularization matrix equals the infinite penalty outside the region coordinated with unsupervised pre-training
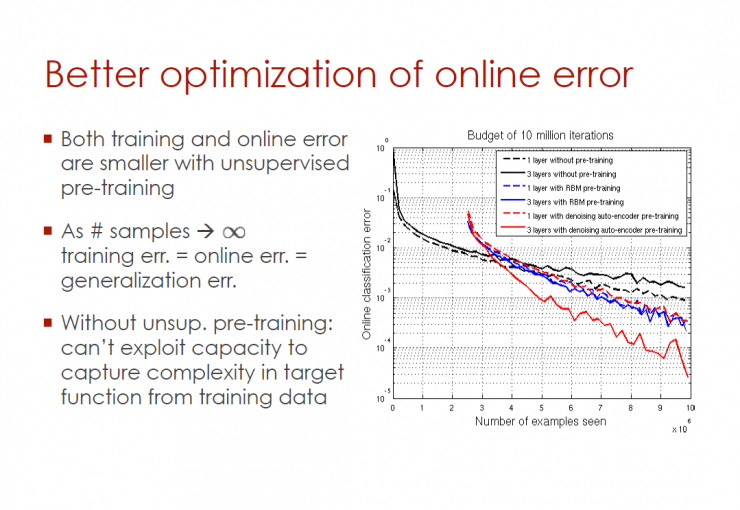
Better online error optimization
In unsupervised pre-training, training and online errors are relatively smaller
When the sample tends to infinity, training error = online error = generalization error
There is no unsupervised pre-training: the ability to capture the complexity of the objective function from training data cannot be exploited
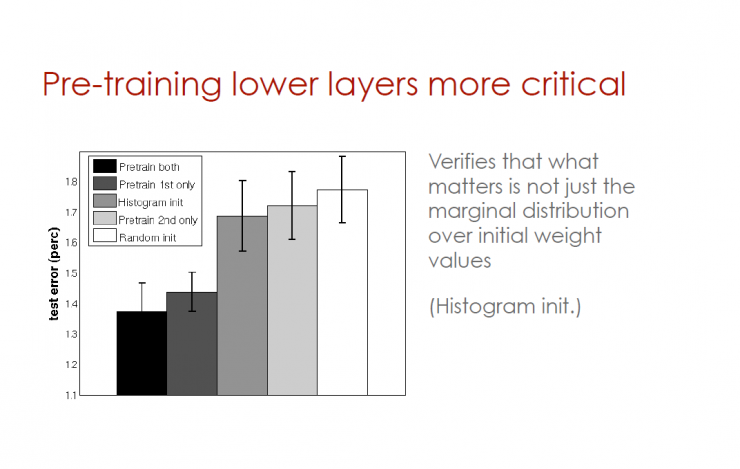
Pre-training lower level plays a more important role
It is confirmed that it is not only the marginal distribution of initial weight values ​​that is important.

Credit allocation problem
Even with the correct gradients, the lower layers (which are farther from the prediction layer and closer to the input layer) are the hardest to train.
The lower level benefits most from unsupervised pretraining.
1. Local unsupervised signal equals extraction/stripping factor
2. Temporary stability
3. Sharing information between multiple modalities
Is credit allocation/error information not easily circulated?
Is credit allocation problem related to the increasing difficulty of credit allocation over time?

Layer-local learning is important
Initializing each layer of an unsupervised deep Boltzmann machine will be of great benefit.
Initializing each layer of unsupervised neural network to RBM will bring great benefits.
Layer-local learning helps all training layers away from the target layer.
Not only will there be unsupervised prior effect.
It is difficult to jointly train all layers of a deep structure.
The use of a layer-local learning algorithm (RBM, automatic encoder, etc.) for initialization is an effective means.

Semi-supervised embedding
Use one or three instances for expressing proximity concepts (or non-neighboring concepts)
The closeness is considered to be the relationship between intermediate representations of similar concept pairs, removing the characterization of randomly selected similarity concept pairs
(Weston, Ratle & Collobert, ICML'2008): Enhancing the efficiency of semi-supervised learning by combining unsupervised embedded standards with supervised gradients

Slowly changing characteristics
Continuous images in video = similar
Randomly selected image pairs = dissimilar
Slowly changing features may refer to interesting abstract features

Learn the dynamic characteristics of deep networks
Before fine-tuning - after fine-tuning

Learn the dynamic characteristics of deep networks
When weights increase, they will fall into the domain of attraction (the “quadrants†do not change).
Initialization updates have a significant impact ("critical period").
In an attractive domain with good generalization characteristics, unsupervised pretraining is initiated.

Instance sorting and selection
Course Study (An Extended Learning Method) (Bengio et al, ICML'2009; Krueger & Dayan 2009)
Start with a simple instance
In deep structures, more rapid convergence is achieved and local minima are obtained.
Is the ordering and selection of instances the same as regularization matrices with optimized effects?
Influential dynamic feature learning will have a major impact.
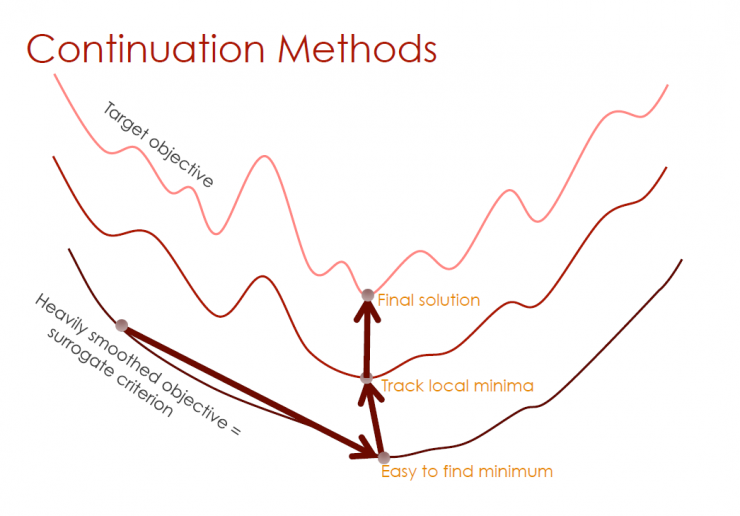
Continuation

As a Continuation Method Course Learning Method
Training sequence
Simple example reaches initial peak
Gradually assign more difficult instances to more weight until the target distribution is achieved

Important information (take-home messages)
Breakthrough in learning complex functions: deep structure with distributed representation.
Multi-layer latent variables: During the sharing of statistical results, multi-level latent variables may increase exponentially.
The main challenge: training deep structures.
RBMs allow quick reasoning, and stacked RMBs/stacked autocoders allow fast approximate reasoning.
The unsupervised pretraining of the classifier is just like optimizing the online error of a strange regularization matrix.
Reasoning approximations and dynamic feature learning play an important role with the model itself.

Some open questions:
Why is it difficult to train deep structures?
Why is learning dynamic characteristics important?
How to reduce the difficulty of joint training all layers?
How to sample more efficiently from RBMs and deep production models?
Do you need to supervise the quality of unsupervised learning in deep networks?
Are there other ways to guide the intermediate representation of training?
How to capture scene structure and sequence structure?
Summary : In this article, we mainly talked about the deep belief network, DBN, unsupervised learning, noise reduction and other related content, and why they are applied to the field of artificial intelligence. As Yoshua Bengio's speech in 2009, it is quite forward-looking, hoping that in-depth learning can give you inspiration.
PS: This article was compiled by Lei Fengnet and refused to be reproduced without permission!
Via Yoshua Bengio
Langrui Energy (Shenzhen) Co.,Ltd , https://www.langruibattery.com