1 BP neural network overview
BP neural network is a type of multi-layer feedforward neural network based on error back propagation (BackPropagation, BP for short) algorithm. BP algorithm is by far the most successful neural network learning algorithm. When using neural networks in real tasks, most of them use BP algorithm for training. It is worth noting that the BP algorithm can be used not only for multi-layer feedforward neural networks, but also for other types of neural networks, such as training recurrent neural networks. But when we usually say "BP network", it generally refers to a multi-layer feedforward neural network trained with BP algorithm.
2 Feedforward process of neural network

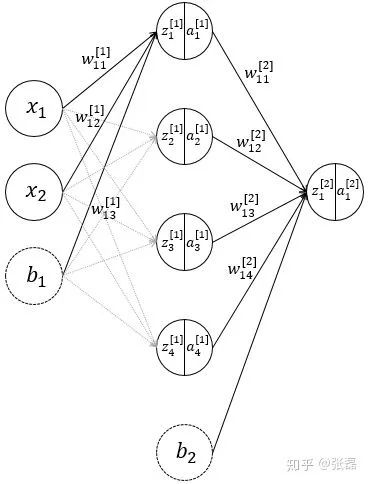
Schematic diagram of neural network structure
The above process is the forward propagation process of the neural network. The feed forward process is also very easy to understand and conforms to human normal logic. The specific matrix calculation expression is as follows
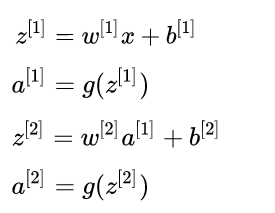
3 Backward error propagation (BP process)

Our task is: given a set of data sets, which contain the input data and the actual results of the output, how to find a set of optimal neural network parameters, so that the network's calculated guesses can best match the true values?
3.1 The loss function of the model
In order to achieve this goal, this is converted into an optimization process. For any optimization problem, there will always be an objective function. In the problem of machine learning, we usually call this type of function: loss function (loss function) function), specifically, the loss function expresses the error between the estimated value and the true value. Abstractly, if the speculation of the model is expressed as a function as 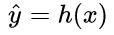 (The function letter here is derived from the word "assume hypothesis"). For input data with m training samples, the loss function can be expressed as:
(The function letter here is derived from the word "assume hypothesis"). For input data with m training samples, the loss function can be expressed as:
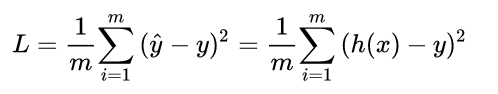
So what is the loss function in this problem? Putting aside the linear combination function, we first focus on the final activation function, which is 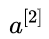 The value of sigmoid function has good functional properties, and its value range is between 0 and 1. When the independent variable is large, it tends to 1, and when it is small, it tends to 0. Therefore, the loss function of the model can be defined as follows:
The value of sigmoid function has good functional properties, and its value range is between 0 and 1. When the independent variable is large, it tends to 1, and when it is small, it tends to 0. Therefore, the loss function of the model can be defined as follows:
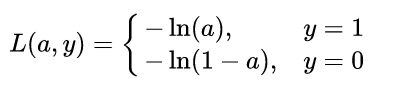
It is not difficult to find that because of the classification problem, the true value can only be taken from 0 or 1. When the true value is 1, the closer the output value a is to 1, the smaller the loss; when the true value is 0, the closer the output value is At 0, the smaller the loss function (you can draw it yourself 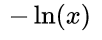 Function curve). Therefore, the piecewise function can be integrated into the following function:
Function curve). Therefore, the piecewise function can be integrated into the following function:
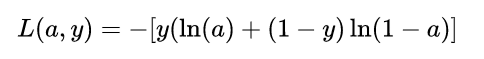
This function is equivalent to the above piecewise function. If you understand the basic principle of the Logistic Regression model, the loss function is completely consistent with it. Now that we have determined the function form of the loss function of the model with respect to the output a, the next question is naturally: how to calculate the loss Function to optimize the parameters of the model.
3.2 The reverse propagation process based on gradient descent (reverse derivation of the loss function)
Here is some prerequisite knowledge, mainly to understand the principle of gradient descent (gradient descent) optimization algorithm, here I will not expand on this method, readers who do not understand can check my previous simple and clear about gradient Article introduced by descent method-> [link]. Since it will be extremely cumbersome to fully expand the loss function of the neural network, here we first proceed with the step-by-step derivation according to the loss function on the output a obtained above.
The core point of BP is back propagation. In essence, it is actually the process of inverse derivation of the final loss function of the model. First, we need to go from the output layer to the hidden layer. 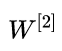 To be guided, that is to say
To be guided, that is to say 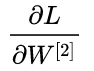 , Here we need to use the chain derivation rule in the derivation method. We first find the 2 necessary derivatives
, Here we need to use the chain derivation rule in the derivation method. We first find the 2 necessary derivatives 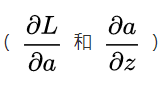 :
:



Bolier Manometer,Square Pressure Gauge,Square Manometer With Capillary,Square Manometer
ZHOUSHAN JIAERLING METER CO.,LTD , https://www.zsjrlmeter.com