In this article, the author used a "true and false news" data set and a Naive Bayes classifier to successfully develop a text classification model. The model can quickly determine the trueness and falseness of an article based on the content information in the text.
"I haven't waited for the truth to be ready. Lies have already run through most of the world."
--Winston Churchill
Since the US presidential election in 2016, “false news†has been the dominant topic of politics. Many political authorities said that political biases and false news reports have had a tremendous impact on the election results. However, Stanford University and New York University researchers expressed doubts about this statement. But no matter what, false news reports are indeed using social media such as Facebook to be widely disseminated on the Internet.
l "What is fake news?"
"Fake news" refers to news that is obviously misleading. But recently, the development of social media and social language is changing this definition. Now, some people use the word “false news†to refute the facts that are contrary to their opinions. The most prominent example is the US President Trump. Therefore, such a very vague definition is actually very easy to use maliciously.
The data science community has taken practical steps to respond to the challenge of "false news." Recently there has been a Kaggle-style competition called "Fake News Challenge"; Facebook is also using artificial intelligence to filter false news reports from user information. In fact, combating false news is actually a very typical text classification task, and the solution to the problem is also very simple, that is, to develop a model that can tell the truth of the news.
And this is exactly what I plan to do. I collected a number of news reports as a database for model development. These news reports are true and false and mixed. In order to develop a model that can identify the trueness of the article, I also used a Naive Bayes classifier in my training.
l Data collection
My training data includes “real news†and “false newsâ€. The data collection process is also divided into two parts: true and false. The collection of false news is very simple. Kaggle has released a fake news data set that includes 13,000 news articles published during the 2016 election, so the source of false news can be obtained from this data set.
However, the acquisition of real news is much more difficult. In order to get real and reliable news coverage, I used a website called "AllSides". This website is dedicated to publishing political news reports and commentary articles. Therefore, the authenticity of its news is relatively guaranteed. Articles on the AllSides website are based on themes (environment, economy, birth, etc.) and political bias (left, right, and middle). The reason why AllSides is used is because this website allows me to directly obtain thousands of relatively true articles from numerous political reports. In addition, AllSides also supports the download of the full text of the article, but the "New York Times" will not work. After a period of data collection, I finally collected 5279 "real news." These "real news" were published between the New York Times, the Wall Street Journal and the National Public Radio and other media agencies from 2015 to 2016.
The final version of the data set contains a total of 10,558 news reports, with the title of the article, the full article content, and the true and false label of the article. All data content can be clicked to view this github.
l goals and expectations
At first I knew that this modeling task was difficult to be perfect. In fact, our task is to develop a classifier that distinguishes between true and false news, and to use new discoveries from the development process to build more complete and accurate models. Initially, I think that distinguishing between true and false news is almost the same as detecting spam.
Developing a model based on the countvectorizer (number of vocabularies) or "tfidf matrix" (using vocabulary in other articles in the dataset) can only achieve this effect. These two models generally ignore the important factors such as "word ordering" and "text layout." For example, two articles with the same number of words are likely to express completely different contents. I don't expect my model to be able to handle word overlapping news reports. Compared to this, I would like to get some valuable insights and experience from this modeling process.
l Modeling
Since this model is about text classification, I used a NaiveBayes classifier.
What really needs to be done to set up such a model is to convert the text ("countvectorizer" vs "tfidfvectorizer") and select the text type (title or full text), so I need to deal with four pairs of reconfigured data sets.
The next step is to choose the optimal parameters for "countvectorizer" or "tfidfvectorizer". In fact, it is to use some of the most commonly used words or phrases, lowercase, delete pause words (such as the, when, there) and so on.
In order to test the performance of multiple parameters and their parameter combinations more efficiently, I used the "grid search" function of Sci-kitLearn. For more information on how to tune algorithm parameters, click on the text to view the tutorial.
After the "grid search" test, I found that the "countvectorizer" and full-text training are more suitable for my model. The best parameters of "countvectorizer" are "non-small-case" and "double-word phrases". The optimal frequency of words appearing in the text library is three times.
As I mentioned in the previous article, my expectations for this model are not high. Therefore, the outcome of this model's final output was surprising to me and even somewhat puzzled. The cross-validation accuracy of the model is 91.7%, the recall value is 92.6%, and the AUC value is 95%.
The following is the ROC curve of this model:
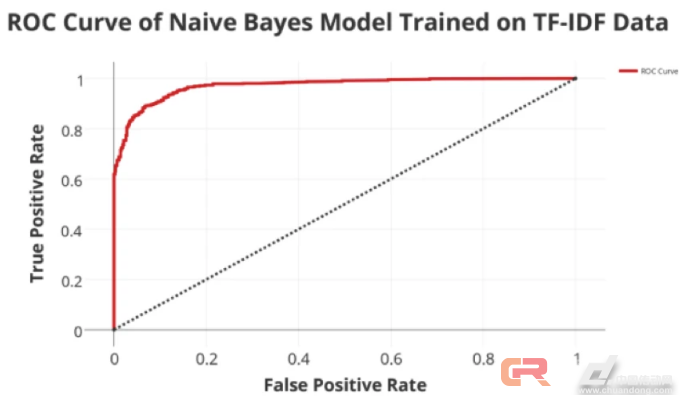
If I were to choose a threshold on this graph, I would choose a threshold where FPR is around 0.08 and TPR is around 0.90. Because at this point the trade-off between FPR and TPR is equal.
l Results and summary
These scores are not really the most important, and the true test of model performance has made it discriminate against news reports in non-training data sets.
In the remaining 5234 news reports in the false news data set, the model correctly identified 88.2% of them, which is 3.5% lower than my cross-validation accuracy, but in my opinion this is already quite good.
I have made this assumption: it is difficult for the model to classify news reports. As it turns out, my hypothesis is wrong.
Although the model I developed looks pretty good, given the complexity of the task, this is likely to be just a representation.
For better understanding, let us first look at the words "most false" and "most true" in the data.
I borrowed a technique from Kevin Markham of the "Data Academy" and found the "fake" and "most true" words in the news report data set.
This work starts with a two-column, 10,558-line table (word count in a text library). The first column represents the number of occurrences of a word in a "false news", and the second column represents the number of occurrences of a word in a "real news". The total number of occurrences of a word in "false news" is divided by the number of "false news". "True news" is the same operation.
Then, I created a new column to represent the ratio of "false news" and "real news" (false news/true news). To avoid conditional errors in the result (divisor cannot be zero), I added 1 to all data values. This ratio can really show intuitively how "true" or "false" a word really is, but it is definitely not perfect. The logic is very simple. If a word appears in many “false news†and only appears in a few “real newsâ€, the ratio of the word will be very large.
The following are the top 20 and most true words in my data set.
The results reflected in these two charts are very confusing--the "most spurious" table contains some typical Internet terms such as PLEASE, Share, Posted, html, and some words that do not exist at all, such as "tzrwu" ". The "most true words" are mainly high-frequency words and politicians' names in political articles. These words account for 60%. Seven of these 20 words are names of politicians. This raises the question: Is a political article more likely to be true? Of course not, many of these political articles are scattered with false rumors about politicians.
There is also a problem with this modeling process - these topics are subject to a large degree of overlap. As we have seen above, the frequency of occurrence of a word in "real news" is not as frequent as in "false news". Being tall does not necessarily mean that the article containing the word is necessarily false. This can only mean that the word is more common in false news.
In fact, the selection of these news reports is very subjective. The "real news" data used by the model was selected by me. The "false news" was selected by "BSDetector" organized by Daniel Sieradski. Therefore, there has been a strong subjectivity in determining the true and false aspects of these news reports. The reason that the names of politicians can enter the "most true words" list is because most of the articles in the "real news" database are political news reports, and these news reports are indeed relatively reliable sources of news.
In conclusion, although a standard NaiveBayes text classification model can indeed provide some ideas for solving the problem of social media publishing false news, from a professional point of view, a more powerful deep learning tool should be used to combat false news and misrepresentation. The remarks.
Distinguishing between true and false news has brought a whole new challenge to the data science community. In most machine-learning tasks, the distinction between categories is very clear, but in this case, the boundaries between true and false news are very blurred. This case once again proves a concept in the data science community - sometimes sensitivity and familiarity with data are even more important than models and tools.
Electronic Cigarette Quit Smoking Closed System Vape Pod,Maskking 2ml 500puffs Disposable Electronic Ecigarette Vape Pen
High-GT body,Aluminum alloy+PC mouthpiece.
Big vapor and good taste.Easy to carry on.
AAA350mAh battery,450+ puffs with laboratory test.
11 flavors for 11 colors, more colors and flavors are available.
Maskking Vape,Maskking Vape Pen,Maskking High Gt
Nanning Goodman Technology Co.,Ltd , https://www.goodmentech.com