Long Short-Term Memory (LSTM) is a kind of time recursive neural network (RTM), which is suitable for processing and predicting important events with long intervals and delays in time series. After many years of experimentation, it is usually better than RNN and HMM work better. What is the working principle of LSTM? In order to tell the concept, a classic article of chrisolah was handled, hoping to help readers.

Recurrent neural network
When humans come into contact with new things, they do not think from scratch. Just as you read this article, you will understand each word based on previous knowledge, instead of giving up everything and start learning again from the letters. In other words, your thinking is continuous.
The emergence of neural networks aims to give the computer the function of the human brain, but for a long time, the traditional neural network can not imitate this point. This seems to be a serious drawback, because it means that the neural network can't infer what is going to happen from what is happening now, that is, it can't classify every event that happens in the movie smoothly.
Later, the emergence of recurrent neural networks (RNNs) solved this problem by adding loops to the network, which allows information to be "remembered" longer.
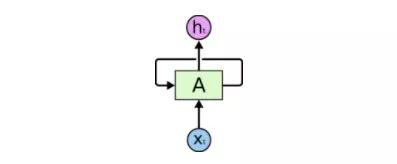
RNN has a loop
The above figure is a large neural network A. After some data xt is input, it outputs the final value ht. The loop allows information to pass from the current step to the next step.
These cycles make it seem somewhat mysterious. But if you think about it, you will find that it is not much different from an ordinary neural network: a RNN is equivalent to multiple copies of a neural network, and each copy passes its own collected information to its successors. If we expand it, it looks like this:
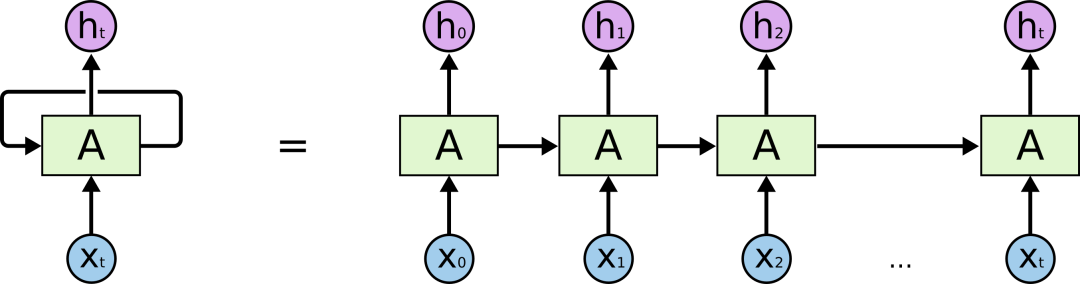
Expanded RNN
This chained nature reveals the close relationship between RNNs and sequences and lists. In a way, it is a natural neural network architecture designed specifically for this type of data.
Practice also confirms that RNN is indeed useful! In the past few years, it has achieved incredible success in various tasks: speech recognition, language modeling, machine translation, image subtitling... The application scenario is very broad. A few years ago, the current Tesla Ai Director Andrej Karpathy wrote a blog entitled “The Unreasonable Effectiveness of Recurrent Neural Networks†that specifically described the applicability of “unreasonable†RNN. Interested readers can go and read it.
In the article we can find that the key to this applicability is the use of "LSTM". This is a very special kind of RNN. All things that can be done with RNN, LSTM can do it, and compared to the regular version, it will perform better in many tasks. So here we take a look at what is LSTM.
Long-term dependence
One of the most attractive aspects of RNN is that it can connect previous information to the current task. For example, we can use the previous video image to understand the image of this frame. If this link can be established, its future will be limitless. So can it really do it? The answer is: not necessarily.
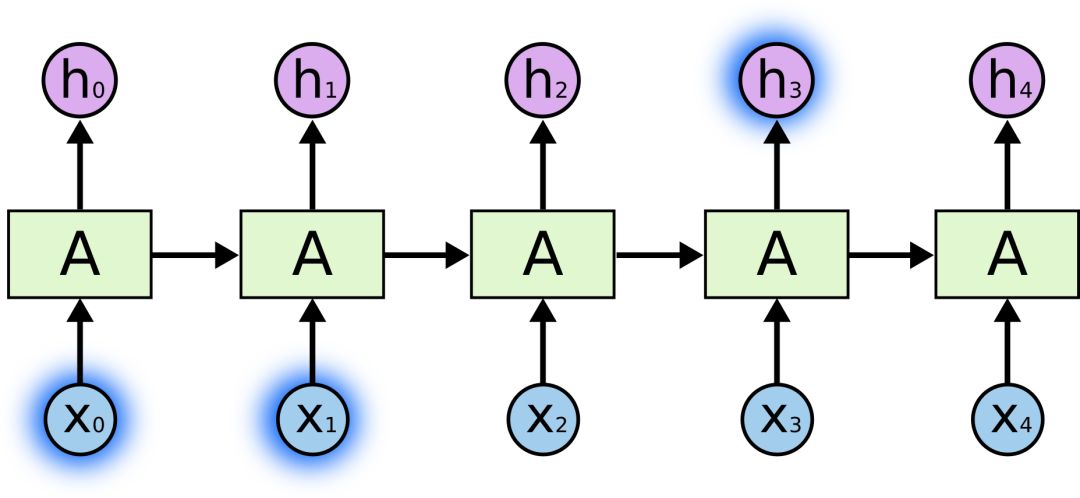
Sometimes we just need to look at the most recent information to perform the current task, such as building a language model that predicts the next word based on the previous word. If we want to predict the last word of the phrase "clouds floating in the sky," the model does not require any further semantic context - obviously, the last word is "cloud." In this case, if the gap between relevant information and target location is small, RNN can fully learn to use previous knowledge.
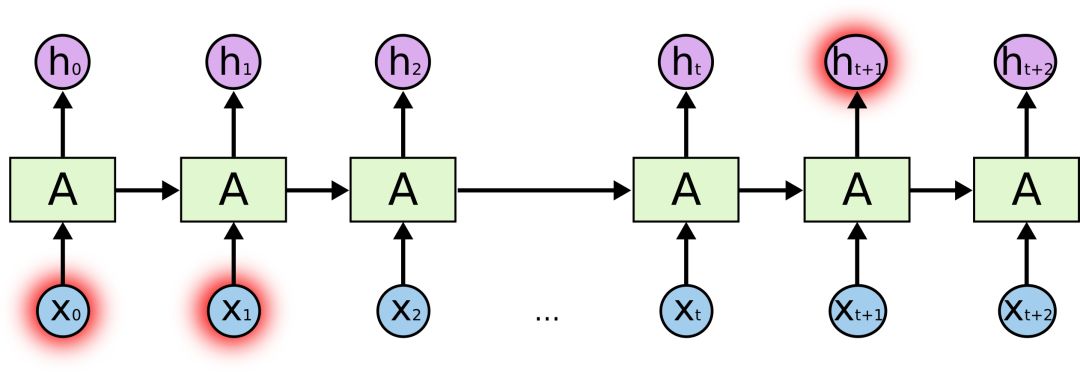
But sometimes we also hope that the model can be linked to the above to understand, such as predicting "I grew up in France ... I speak fluent French." The last word of this sentence. The most recent information suggests that the word is likely to be the name of a language. If we want to be precise in which language, we need to understand it with "France" at the beginning of the sentence. At this time, the distance between two related information is very far apart.
Unfortunately, as the distance continues to widen, it becomes increasingly difficult for RNN to learn the connection information.
From a theoretical point of view, RNN is absolutely capable of dealing with this long-term dependency. We can constantly adjust the parameters to solve various toy problems. However, in practice, RNN has failed completely. On this issue, Hochreiter (1991) and Bengio et al. (1994) have previously conducted in-depth discussions and will not repeat them here.
Thankfully, LSTM does not have these problems.
LSTM network
The long-term short-term memory network - often referred to as "LSTM" - is a special kind of RNN that learns long-term dependencies. It was first proposed by Hochreiter & Schmidhuber in 1997. After being refined and promoted by many experts and scholars, it has now been widely used due to its excellent performance.
The design goal of LSTM is very clear: avoid long-term dependency problems. For LSTM, “remembering†information for a long time is a default behavior, not something that is difficult to learn.
As we mentioned before, the RNN is a chained form containing a large number of repeating neural network modules. In the standard RNN, these repeated neural network structures are often very simple, such as containing only a single tanh layer:
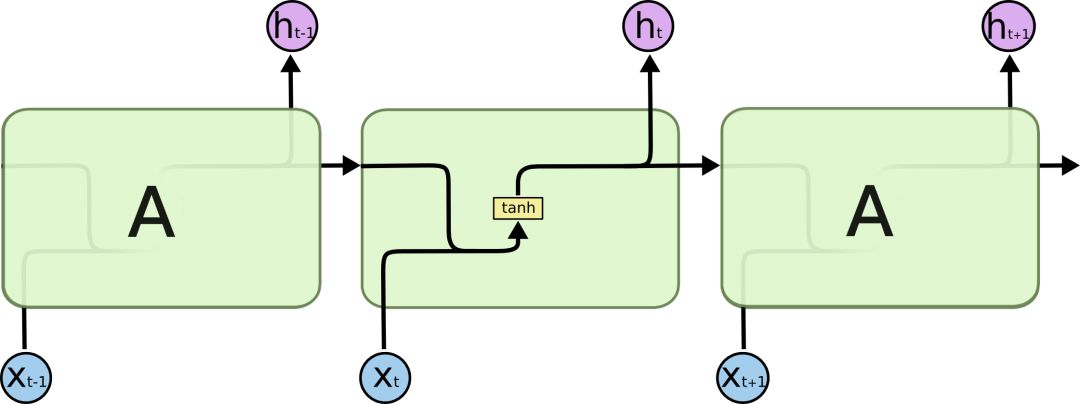
Standard RNN contains only duplicate modules of a single tanh layer
LSTM also has a similar chain structure, but the difference is that its repeated module structure is different, and it is a neural network that interacts in a special way.
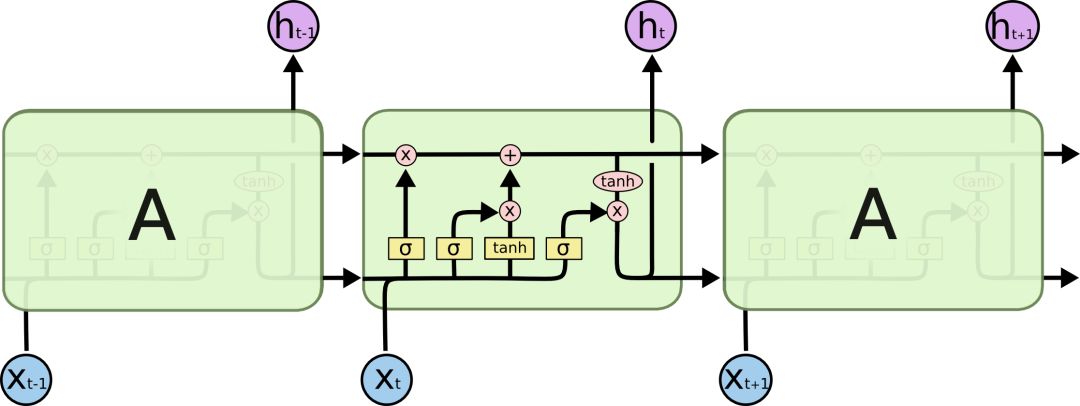
LSTM schematic
Here we first look at these symbols in the figure:

In the diagram, from the output of one node to the input of other nodes, each line passes a complete vector. Pink circles represent pointwise operations such as node summation, while yellow boxes represent neural network layers for learning. The merged two lines represent the connection, and the two separate lines indicate that the information is copied into two copies and will be delivered to different locations.
The core idea behind LSTMs
The key to LSTMs is the state of the cell, which is the horizontal line at the top of the schematic.
The cell state is a bit like a conveyor belt. It can only penetrate the entire chain structure with some minor linear interaction. This is actually the place where information is remembered, so information can easily flow through it in an invariable form.
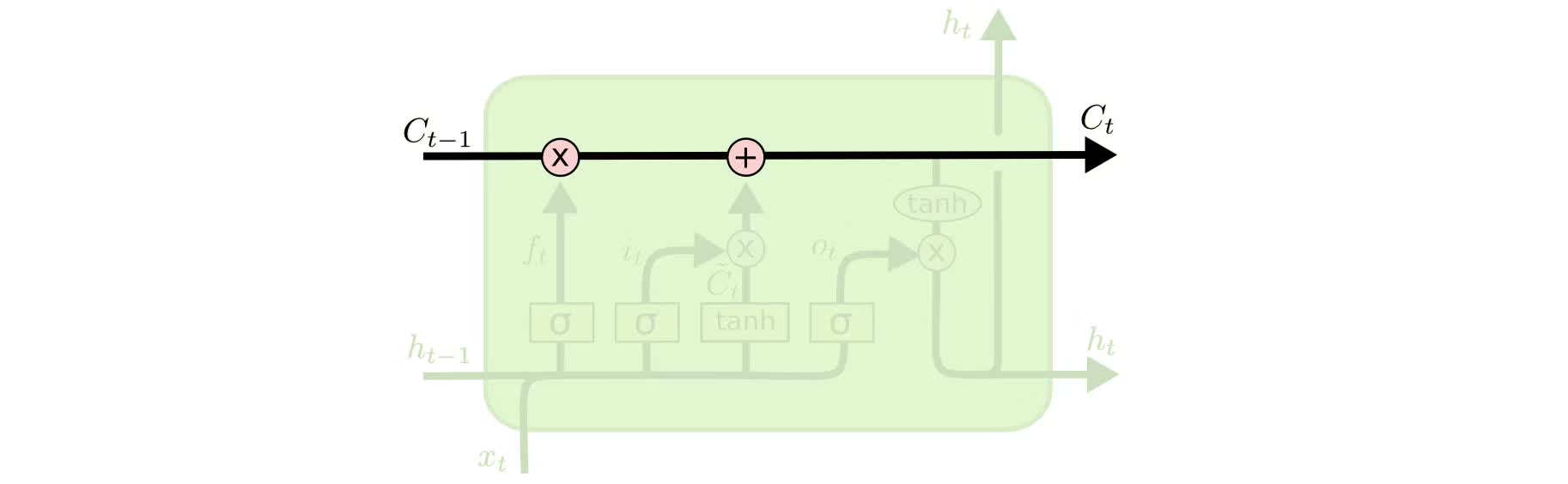
In order to add/delete information in the cell, there are some gates in the LSTM. They determine the way information is passed, including a sigmoid neural network layer and a pointwise dot multiplication operation.

The sigmoid layer outputs a number between 0 and 1, and the dot multiplication operation determines how much information can be transmitted in the past. When it is 0, it is not transmitted; when it is 1, all are transmitted.
There are three LSTM control gates like this to protect and control the status of the cell.
Learn more about LSTM
Let's take a look at what information the cell should delete. The decision to make this decision is the oblivion gate containing the sigmoid layer. For inputs xt and ht-1, the Oblivion Gate outputs a number in the range [0, 1] and places it in cell state Ct−1. When it is 0, all are deleted; when it is 1, all are retained.
Take the language model that predicted the next word as an example. For the sentence “Clouds float in the sky,†the LSTM's cell state remembers the part of the subject of the sentence “cloudâ€, after which the correct pronoun can be determined. When the new subject is encountered again next time, cell will “forget†the part of speech of “cloudâ€.

Let's look at how cells can add new information. This can be divided into two steps. First, LSTM uses an input gate that contains a sigmoid layer to determine which information to retain, and second, it uses a tanh layer to generate a vector, C~t, for this information to update the cell state.
In the language model example, if the sentence becomes "the sky is floating in the clouds, the horse is running on the meadow." The LSTM will replace the forgotten "cloud" part of speech with the "horse's" part of speech.

With oblivion gates and input gates, we can now update the cell state Ct−1 to Ct. As shown in the figure below, ft×Ct−1 indicates the information that you want to delete, and it×Ct indicates the new information.
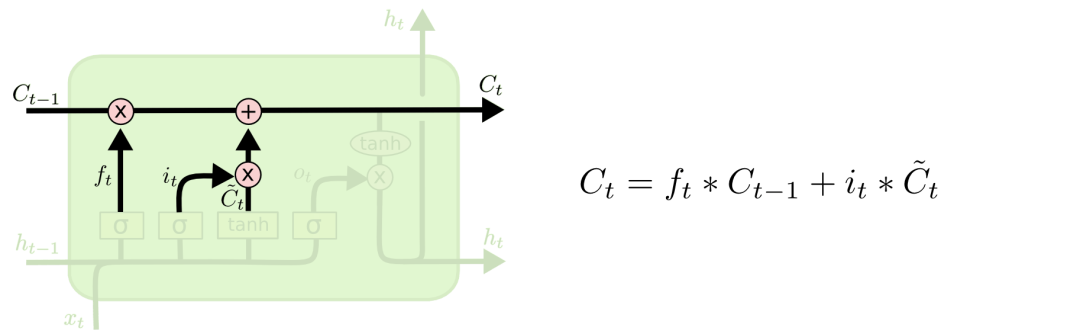
The final output gate determines the output of the LSTM. Its information is based on the status of the cell, but it must be filtered. We first use the sigmoid layer to determine the content of the cell to be output, and then use the tanh layer to push the cell state value between -1 and 1, and multiply it by the output of the sigmoid layer so as to output only the part that we want to output. .
Variants of LSTM
The above introduction is a very general LSTM, but in practice we will also encounter a lot of very different neural networks, because once used, people will inevitably need to use some DIY versions. Although they are not very different, some of them are worth mentioning.
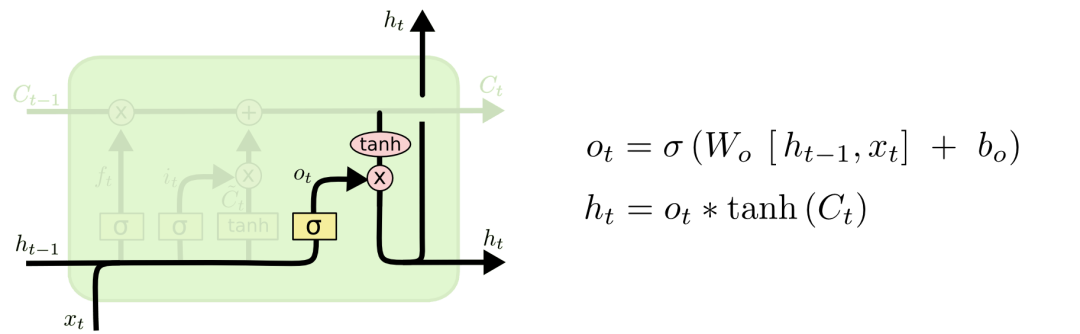
In 2000, Gers & Schmidhuber proposed an LSTM variant with "peephole connections" added. It means that we can observe the status of the cell in the corresponding control gate. The following picture shows peepholes for each door. We can add only one or two places.
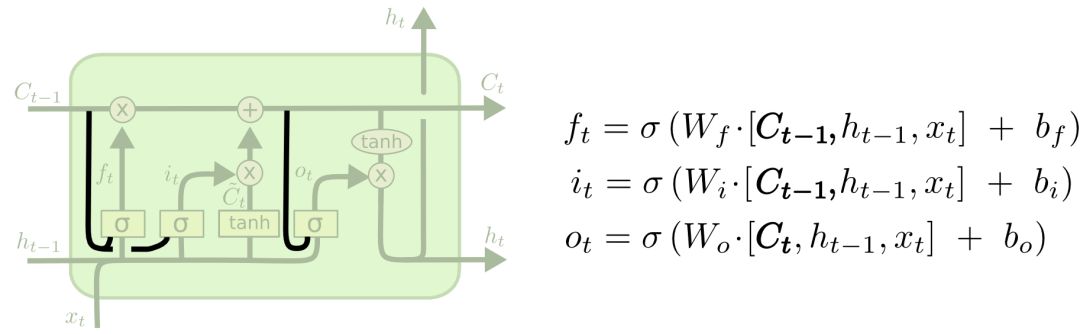
The second variant is to couple the oblivion gate and the input gate so that a module decides what information to add/delete at the same time.
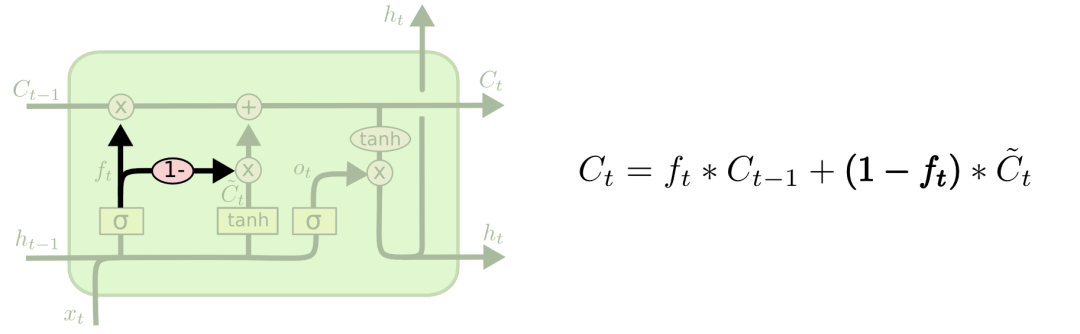
The third, slightly dramatic variant is the LSTM with GRU proposed by Cho et al. in 2014. It combines the oblivion gate and the input gate into an "update gate", merges the cell state and hidden state, and makes some other modifications. The advantages of this model are simpler and more popular.
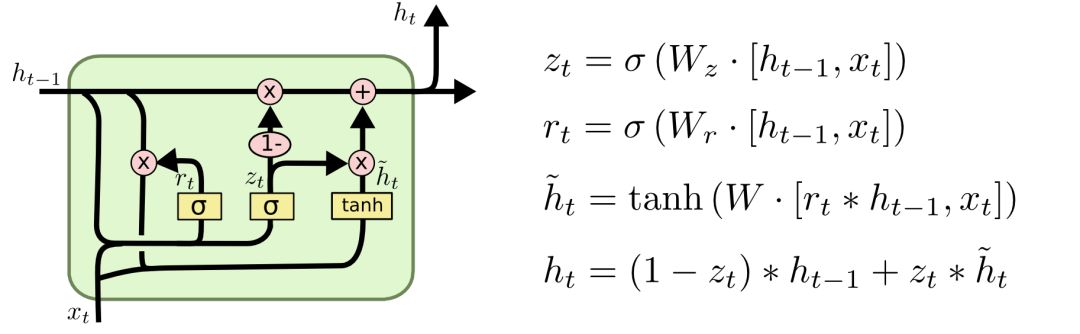
These are just a few of the best-known LSTM variants, and there are many others, such as Yao et al's Depth Gated RNN. In addition, some people have been trying to solve long-term dependence problems in completely different ways, such as Koutnik et al.'s Clockwork RNN.
summary
If you just list a lot of math formulas, LSTM can seem very scary. Therefore, in order to make the readers easier to understand and master, this article produced a large number of visual images, which have also been recognized by the industry and widely quoted in various articles.
The LSTM is an important part of improving the RNN. Although it has achieved fruitful results, we use this as a starting point to explore other research directions on the RNN, such as the Attention Mechanism in the past two years. It is used in the GAN. RNN and so on. It has been an exciting time for neural networks in the past few years and I believe the future will be even more so!
Copper Corrugation Tube
The inner thread copper tube is used in air conditioning products, which can increase the heat exchange area of copper tube and increase the heat exchange capacity of air conditioning heat exchange.
However, this kind of tube is used in the fluorine machine heat exchange inside, can not be used in the fan coil, air conditioning box and other products of the water heat exchange inside.
Freezer Copper Tube,Copper Corrugation Tube,Refrigerator Copper Tube,Air Conditioner Copper Tube
FOSHAN SHUNDE JUNSHENG ELECTRICAL APPLIANCES CO.,LTD. , https://www.junshengcondenser.com